While deploying Large language model , I faced two major issues
- Memory
- Latency
While researching on the solution , I came across this blog (https://medium.com/@quocnle/how-we-scaled-bert-to-serve-1-billion-daily-requests-on-cpus-d99be090db26) which has explored ways to solve this problem. With time I have realized that the best way to understand something is to write a blog on those concepts. I am writing this blog to share my findings on methods to tackle this problem. Some of the method to solve this problems are:
- Knowledge distillation
- quantization
- Pruning
- graph optimization with ONNX and ORT
ONNX file format– ONNX (Open Neural Network Exchange) is an open-source format for representing deep learning models. An ONNX file operates by encapsulating the structure of a deep learning model in a protobuf-based format (Protocol Buffers), defining a computational graph that represents the model’s computation, and providing metadata and attributes for interpretation and execution by runtime engines. The main advantage of this method is ORT (ONNX runtime) This runtime provides ways to optimize the computation graph by using techniques like operator fusion (merging one operator with another so that they can be executed together) and constant folding.

Figure 1:- Sample ONNX graph (https://huggingface.co/blog/assets/81_convert_transformers_to_onnx/graph.png)
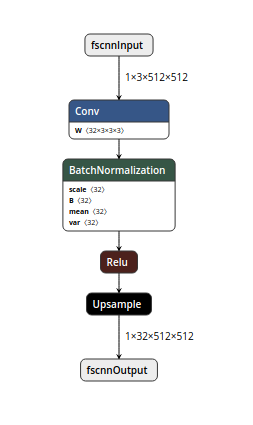{kind=link}
In ONNX graph data flows between nodes and on each nodes certain operations are performed.
Quantization:-In this approach , we represent weights ,activation or other variables with lower precision instead of usual 32 bit floating point (FP32). This not only reduces memory requirement but also computation like matrix multiplication can be performed at much higher speed. This improves inference time considerably.
The first question which comes to our mind is that is it just casting variable to different data types or there is more to it? Simple answer is yes, there is more to it. The Math behind this is simple but yet very elegant.
Suppose we are dealing with a weight matrix whose value varies from -1 to 1 and we want it to be represented in INT8 format. The idea is to discretize this range and map this range to a smaller precision. In case of INT8 number can vary in a range from -128 to 127. For this, we have to calculate a scaling factor (range of original format/range of quantized format) which in this case is (1-(-1))/(127-(-127)). Lets understand this with help of a figure

In this figure we want to project point p which is lying on scale of range (fmax,fmin) to a scale of (qmax,qmin). Let us assume the new point is p1 so by applying concept of ratio and proportion we know p will divide the line in same way as p1 divides the line of new range so ,p/p1=(fmax-fmin)/(qmax-qmin) so p1=p*(qmax-qmin)/(fmax-fmin). In case origin is not aligned then we need to calculate zero point and add it to p1.
Overall this quantization can be categorized into two types:-
Dynamic quantization: In this method quantization happens on the fly and no training is required for this
Static quantization:- In this method we also have to pass small subset of data and the parameter of mapping function is calculated based on this data. This method produces a faster inference time as parameter of mapping function is pre-calculated.
In terms of coding there is not much to add and these links will be sufficient to learn
Optimization and saving file in ONNX format- https://huggingface.co/docs/optimum/onnxruntime/usage_guides/optimization
Quantization of the model
In terms of weight update h = W0x + ∆W x = W0x + BAx . Here BA is the two decomposed matrix which are getting added to the pre-trained weight. Pretrained weights are fixed here. They have also used a scaling factor by which they scale the calculated weights.
I have tried these method on Mistral-7B and it reduced memory uses by almost quarter and inference time by almost half while answer or model output did not change much. I recommend highly to use these method and experience the difference.
Leave a Reply